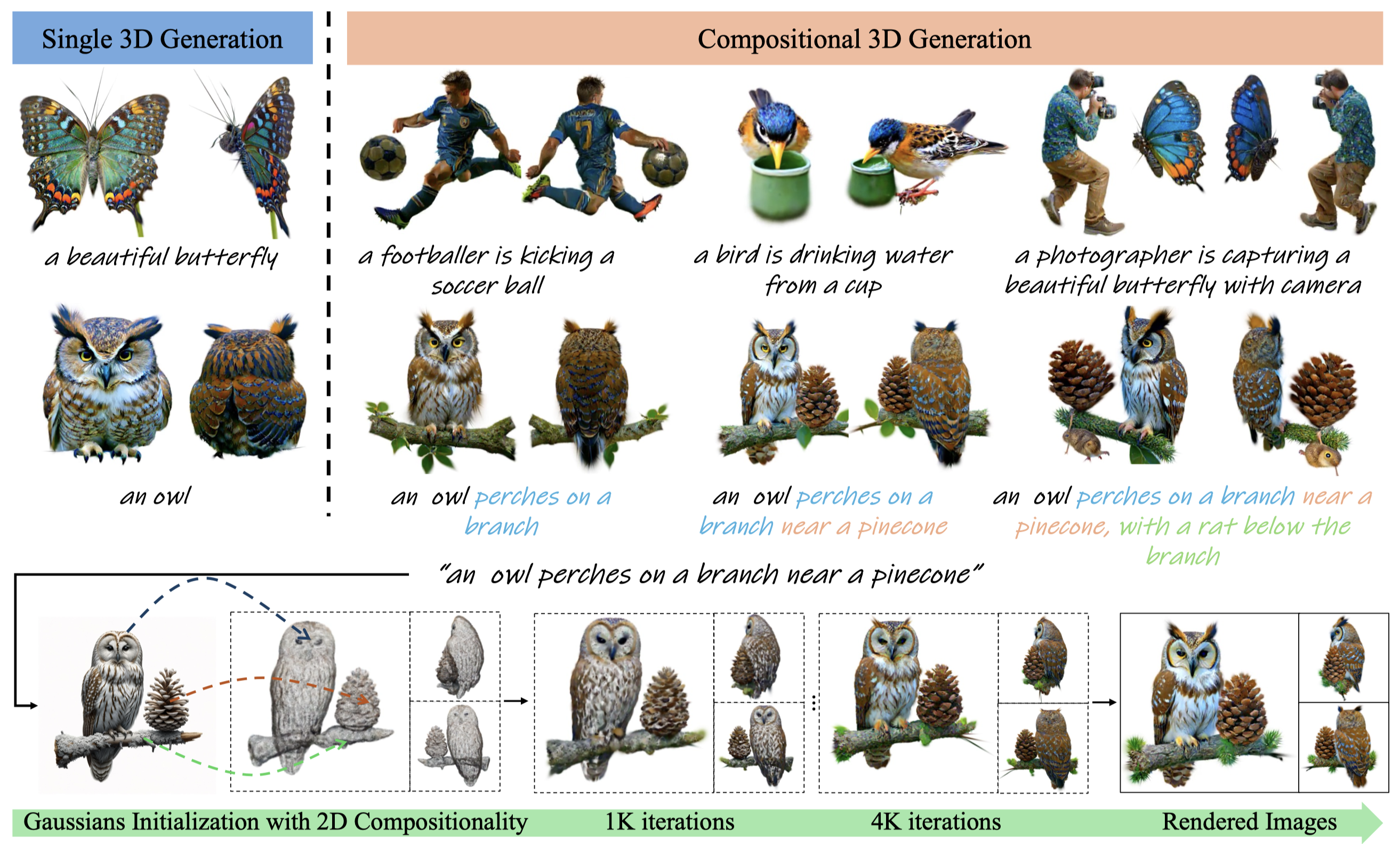
Recent breakthroughs in text-guided image generation have significantly advanced the field of 3D generation. While generating a single high-quality 3D object is now feasible, generating multiple objects with reasonable interactions within a 3D space, a.k.a. compositional 3D generation, presents substantial challenges. This paper introduces CompGS, a novel generative framework that employs 3D Gaussian Splatting (GS) for efficient, compositional text-to-3D content generation. To achieve this goal, two core designs are proposed: (1) 3D Gaussians Initialization with 2D compositionality: We transfer the well-established 2D compositionality to initialize the Gaussian parameters on an entity-by-entity basis, ensuring both consistent 3D priors for each entity and reasonable interactions among multiple entities; (2) Dynamic Optimization: We propose a dynamic strategy to optimize 3D Gaussians using Score Distillation Sampling (SDS) loss. CompGS first automatically decomposes 3D Gaussians into distinct entity parts, enabling optimization at both the entity and composition levels. Additionally, CompGS optimizes across objects of varying scales by dynamically adjusting the spatial parameters of each entity, enhancing the generation of fine-grained details, particularly in smaller entities. Qualitative comparisons and quantitative evaluations on T3Bench demonstrate the effectiveness of CompGS in generating compositional 3D objects with superior image quality and semantic alignment over existing methods. CompGS can also be easily extended to controllable 3D editing, facilitating scene generation. We hope CompGS will provide new insights to the compositional 3D generation. Codes will be released to the research community upon publication.
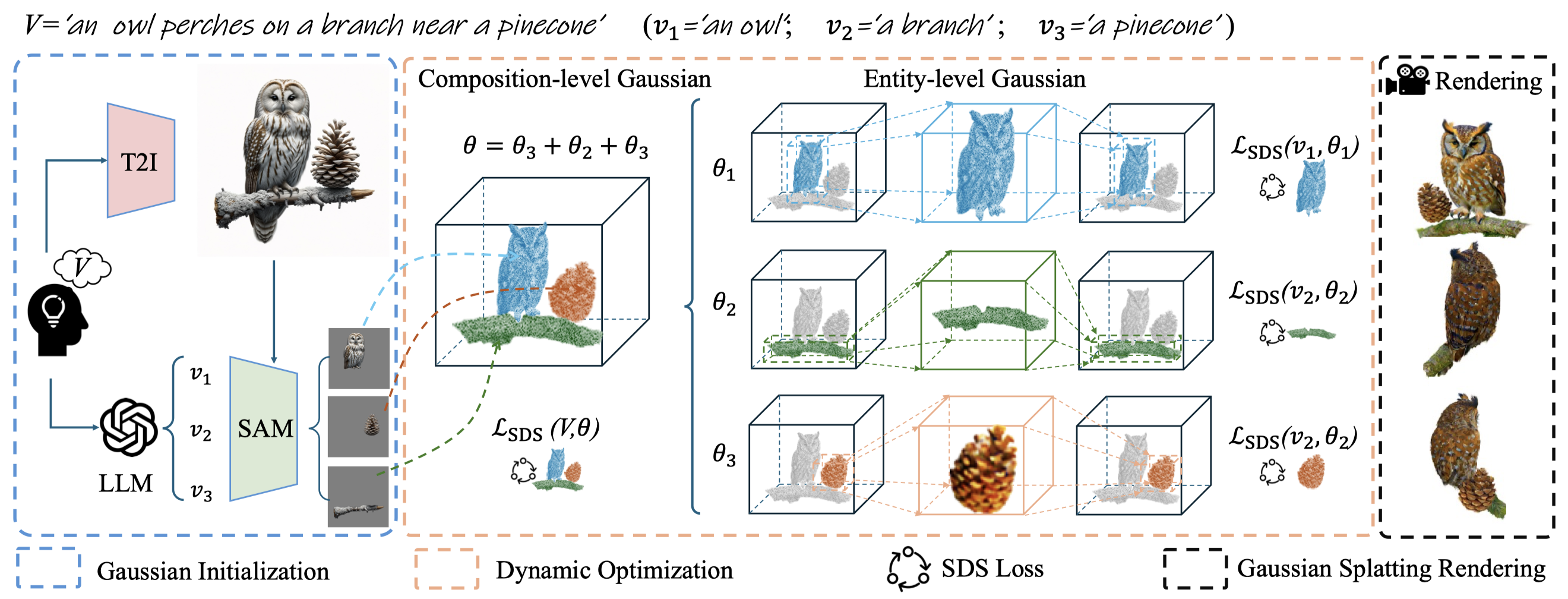
Figure 1. Overall pipeline of CompGS. Given a compositional prompt V, we first use an LLM to decompose it into entity-level prompts v_l, guiding the segmentation of each entity from the compositional image generated by T2I models. The segmented images initialize entity-level 3D Gaussians via image-to-3D models. CompGS employs a dynamic optimization strategy, alternating between composition-level optimization of θ and entity-level optimization of θ_l. For entity-level optimization, COMPGS dynamically maintains volume consistency to refine the details of each objects, particularly the small one.

Figure 2. Qualitative comparisons between CompGS and other text-to-3D models on T3Bench (multiple objects track). Compared to others, CompGS is better at generating highly-composed, high-quality 3D contents that strictly align with the given texts.
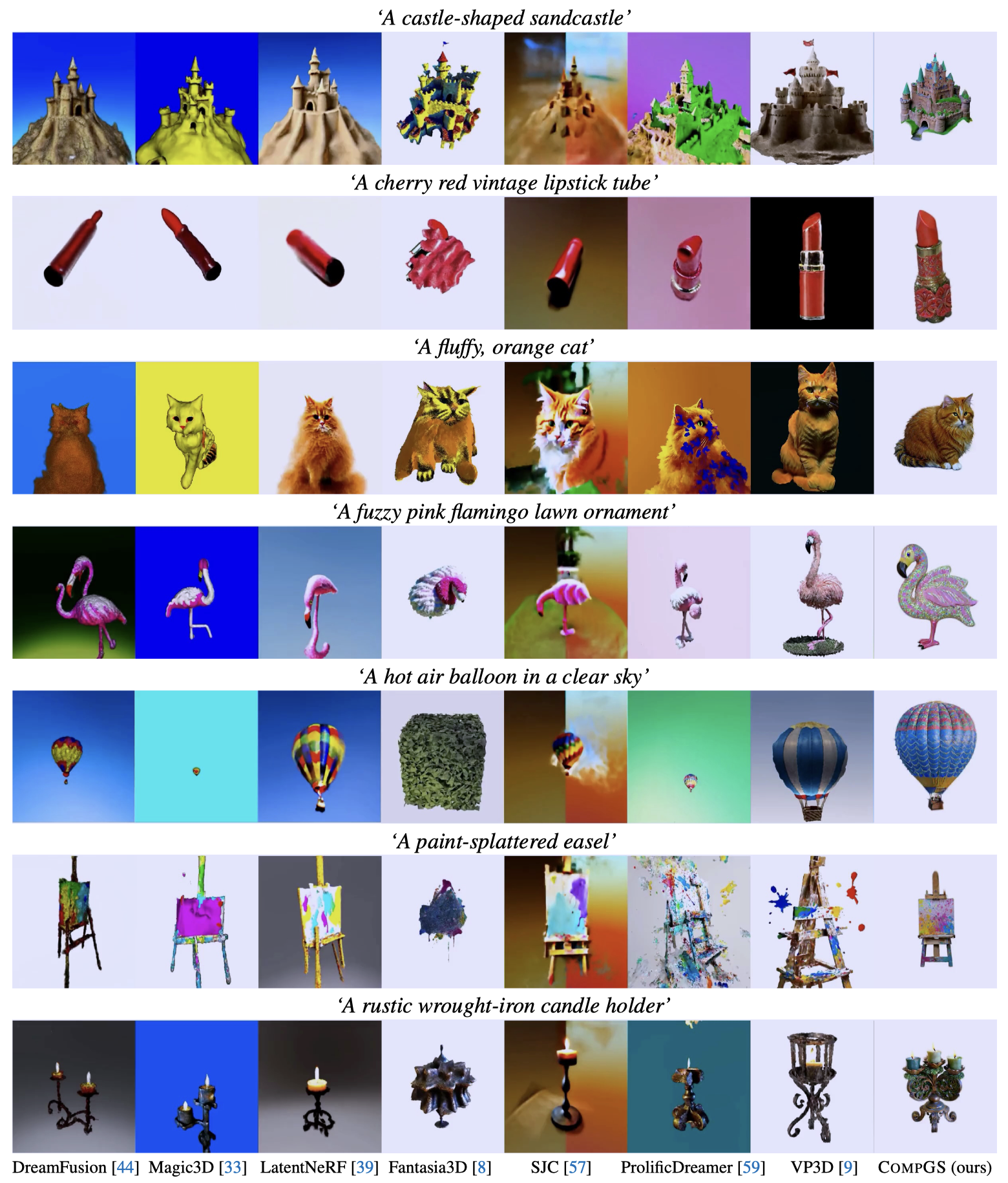
Figure 2. Qualitative comparisons between CompGS and other text-to-3D models on T3Bench (single objects track). Compared to others, CompGS is better at generating highly-composed, high-quality 3D contents that strictly align with the given texts.
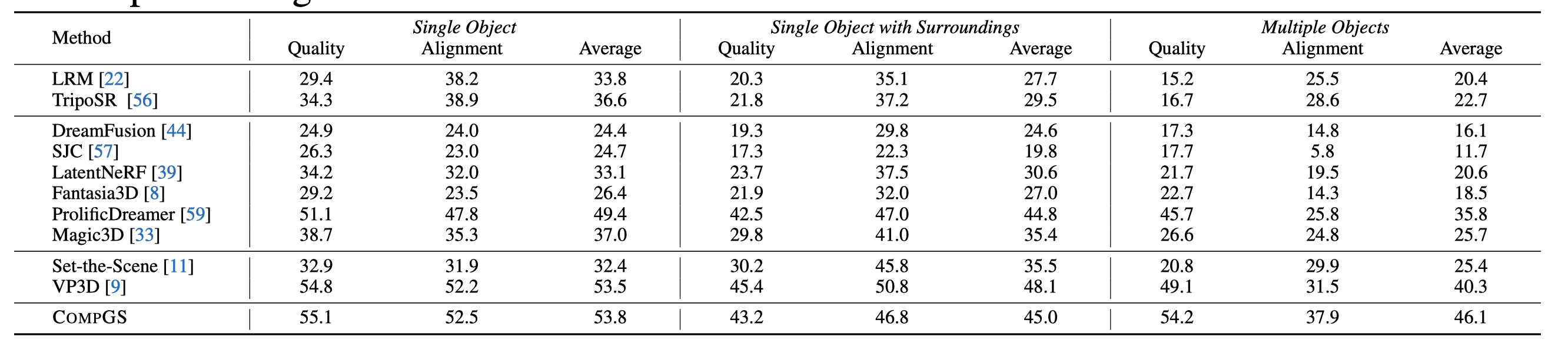
Table 4: Quantitative comparisons with baselines on T3Bench (all tracks). CompGS is compared with feed-forward models, optimization-based models, and models specifically designed for compositional generation.

CompGS provides a user-friendly way to progressively edit on 3D scenes for compositional generation.